- Published on
django-celery-beat의 내부 구조와 활용 노하우
- Authors

- Name
- hongreat
- ✉️hongreat95@gmail.com
업무에서 수도 없이 celery 를 사용하면서 내부적으로 뜯어볼 생각은 별로 안했었는데, 개인 서버를 구축하면서 부터는 celery 나 서드파티 툴들을 자유롭게 뜯어보는 것에 흥미를 느낍니다. 이번 글에서는 beat_max_loop_interval나 tick() 함수의 동작 구조, is_due() 로직 등을 간단하게(?) 정리합니다.
- 1. Celery Beat vs django-celery-beat
- 2. Celery Beat에서 알아두면 좋은 tick(), is_due()
- 3. Max Interval 개념
- 4. Task 결과 저장 여부와 구조
- 5. one-off Task
- 6. 참고자료
1. Celery Beat vs django-celery-beat
기본 구조 차이
DatabaseScheduler는 어떤 역할인가?
- Celery Beat는 기본적으로 파일 기반 스케줄러를 사용하지만, django-celery-beat는 Django의 데이터베이스를 활용하여 스케줄을 관리합니다.
왜 django-celery-beat를 쓰는가?
- 이걸 반드시 써야하는건 아니지만, Django Admin에서 스케줄을 쉽게 관리하고자 했습니다. 굳이 다른걸 쓸필요도 안느껴지기도 했습니다.
- Django ORM을 통해 스케줄을 조회하고 수정하는 것이 용이하다는것도 좋은 점 같습니다.
# django settings.py 예시
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
2. Celery Beat에서 알아두면 좋은 tick(), is_due()
tick이란 한 루프(iteration) 입니다. Celery Beat는 주기적으로 실행할 작업들을 등록해두는데, 이를 정해진 시간마다 Celery worker로 보내는 스케줄러 역할을 합니다. 이때 Beat 내부에서는 다음과 같은 루틴이 반복됩니다.
tick 시작 Beat는 현재 시간을 기준으로 지금 실행해야 할 task가 있는지 확인합니다.
task 발송 실행해야 할 task가 있다면, Celery worker에게 apply_async() 등을 통해 task를 발송합니다.
다음 tick까지 대기 설정된 주기에 따라 잠시 대기한 뒤, 다시 tick이 시작됩니다.
2.1 tick() 함수
여기서 tick() 은 Celery Beat의 핵심 루틴을 담당하며, 주기적으로 실행되어야 할 작업들을 확인하고 실행하는 역할을 합니다. 이 메서드를 통해서 한 번의 "tick"을 실행하는 함수입니다.
현재 시간이 되었거나 지난 task가 있으면
- task를 실행하고 다음 tick까지 얼마나 기다릴지에 대한 판단(?)도 반환합니다.
실행할 스케줄이 없으면
- max_interval만큼 기다리라고 알려줍니다.
소스코드 위치: celery/beat.py
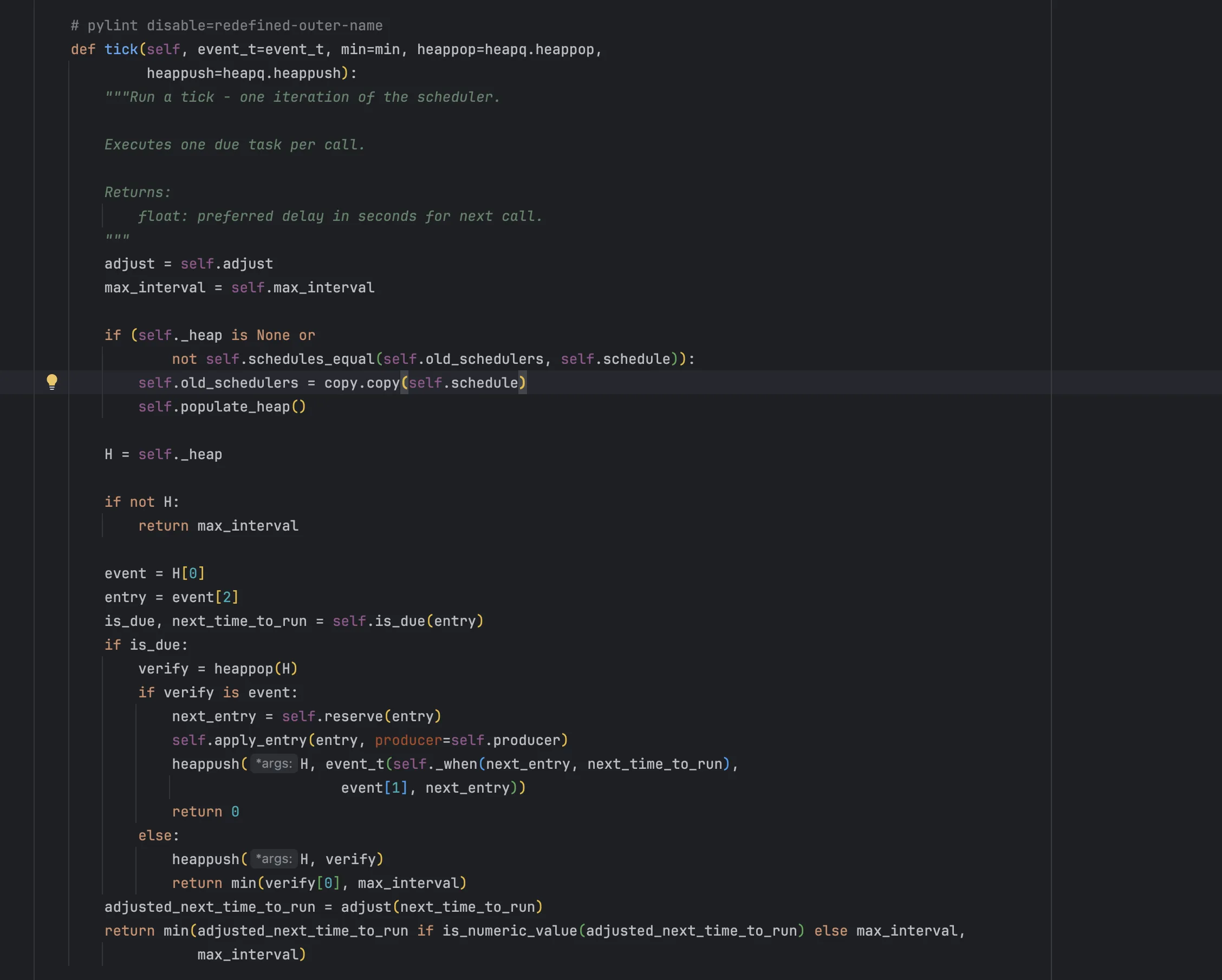
- 소스코드에서
self._heap이란 내부적으로 관리되는 우선순위 큐(heap)가 있고, 실행할 task들을 우선순위에 따라 정렬하여 저장합니다. - 실행할 스케줄이 없으면 max_interval 만큼 기다리라고 알려줍니다. => max_interval
- 우선순위 큐 맨 앞(가장 빨리 실행해야 할 task)을 확인해서 지금 실행할 시간인지 판단합니다.
def tick(self, event_t=event_t, min=min, heappop=heapq.heappop,
heappush=heapq.heappush):
"""Run a tick - one iteration of the scheduler.
Executes one due task per call.
Returns:
float: preferred delay in seconds for next call.
"""
adjust = self.adjust
max_interval = self.max_interval
if (self._heap is None or
not self.schedules_equal(self.old_schedulers, self.schedule)):
self.old_schedulers = copy.copy(self.schedule)
self.populate_heap()
H = self._heap
if not H:
return max_interval
event = H[0]
entry = event[2]
is_due, next_time_to_run = self.is_due(entry)
if is_due:
verify = heappop(H)
if verify is event:
next_entry = self.reserve(entry)
self.apply_entry(entry, producer=self.producer)
heappush(H, event_t(self._when(next_entry, next_time_to_run),
event[1], next_entry))
return 0
else:
heappush(H, verify)
return min(verify[0], max_interval)
adjusted_next_time_to_run = adjust(next_time_to_run)
return min(adjusted_next_time_to_run if is_numeric_value(adjusted_next_time_to_run) else max_interval,
max_interval)
2.2 is_due() 함수
is_due는 현재 시각 기준으로 이 task를 지금 실행해야 하는지 판단하는 핵심 함수입니다. 이 함수를 통해서 지금 task를 실행해야 하면 True, 아니면 False를 반환합니다.
is_due, next_time_to_run = self.is_due(entry)
참고로 next_time_to_run는 다음 실행까지 남은 시간 입니다.
3. Max Interval 개념
max_interval은 말 그대로 tick() 사이의 최대 대기 시간 입니다.
아무런 작업이 없더라도 최소한 이 주기마다 한 번은 tick을 실행하라는 의미 입니다.
- 헷갈릴수도 있는 개념은 * max_interval은 task를 실행하는 주기가 아니고, 스케줄을 확인하는 루프를 멈추지 않고 돌리기 위한 제한 시간입니다. fail-safe 의 개념으로 이해하면 됩니다.
3.1 max_interval의 기본값(Celery Beat vs django-celery-beat)
- Celery Beat의 기본값은 300초(5분)입니다.
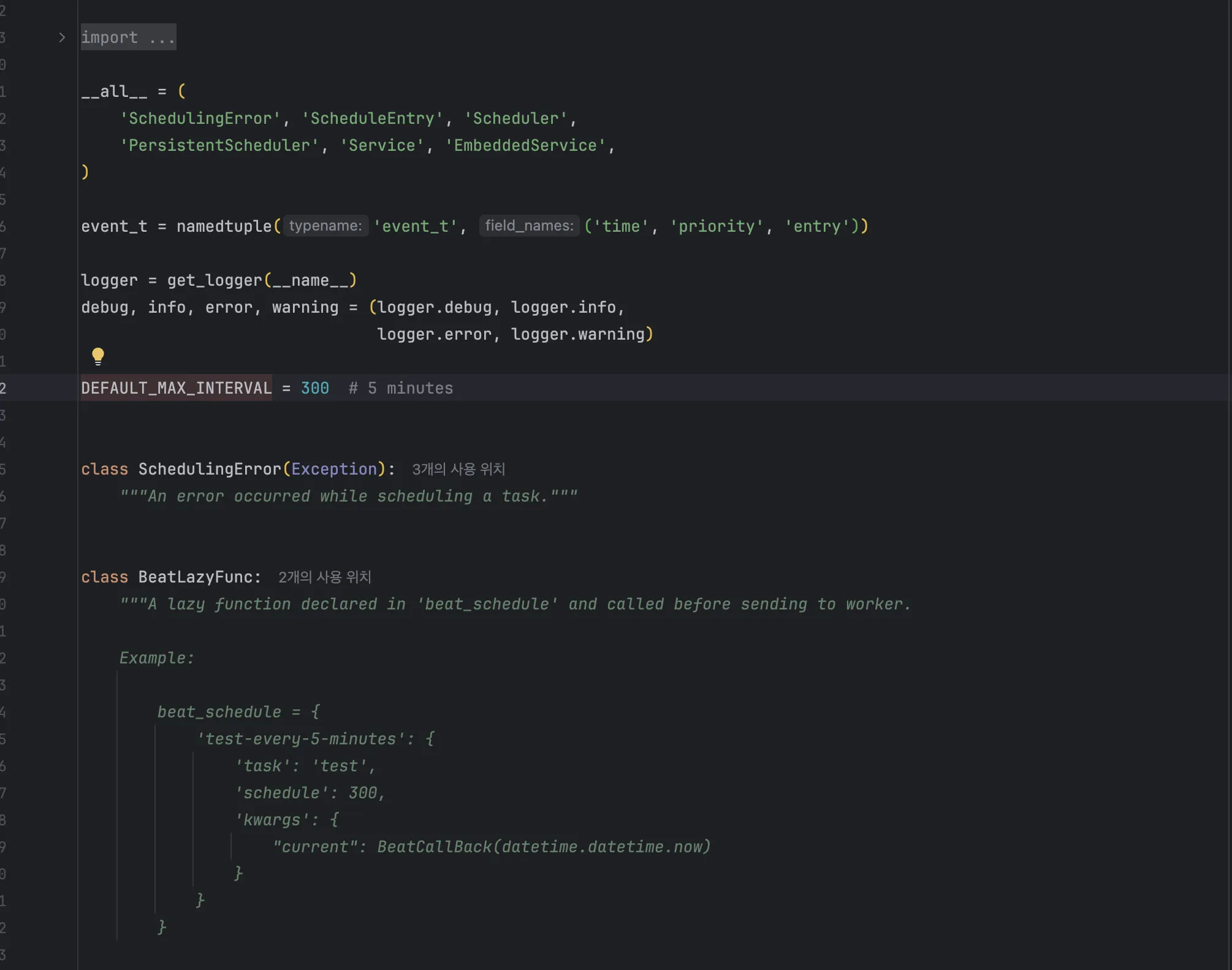
- django-celery-beat의 기본값은 5초입니다.
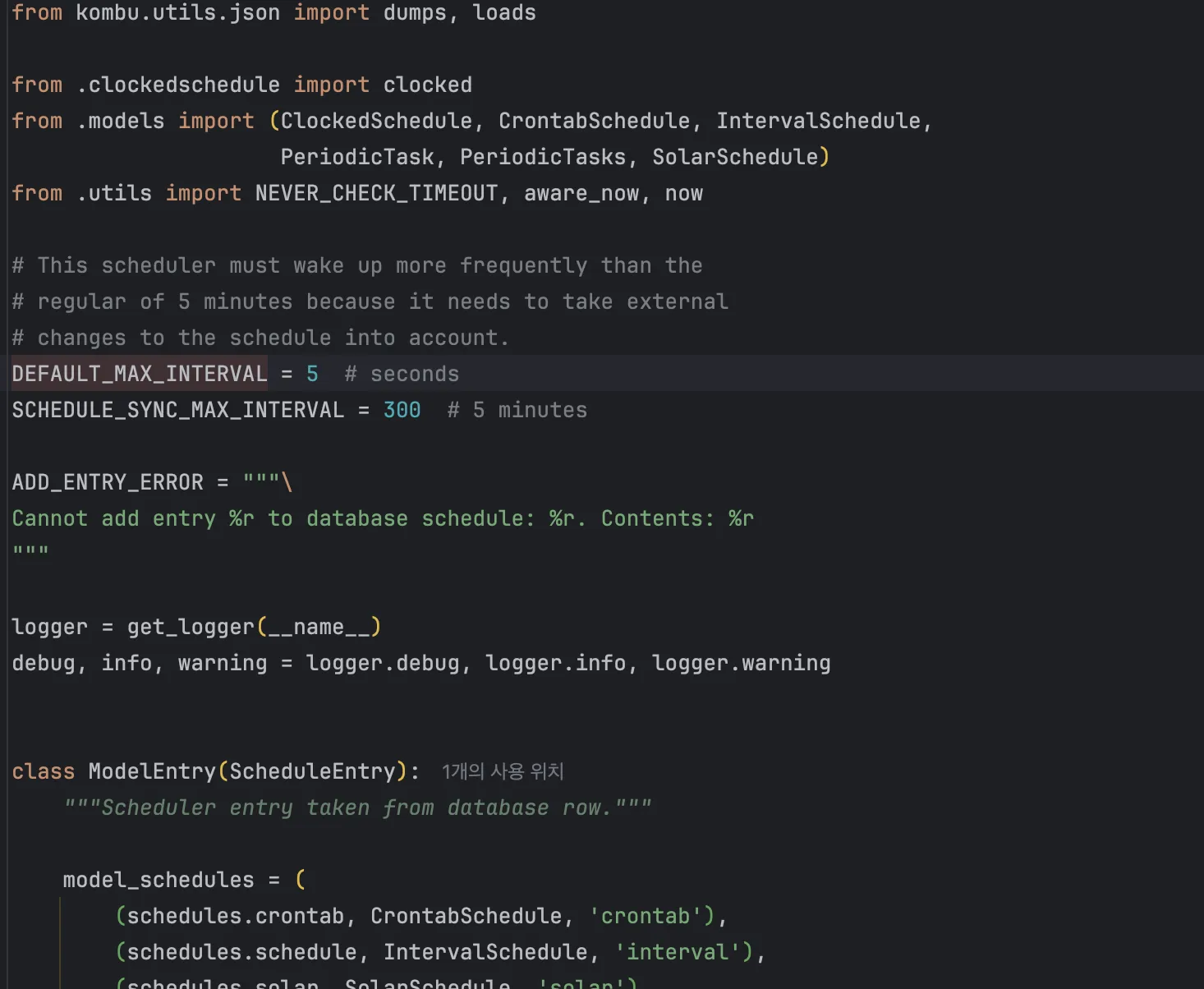
왜 이런 차이가 있을지, 생각해보면 이유는 간단합니다.
- Celery 기본 Beat (celery/beat.py)는 스케줄 정보를 코드 내 메모리에 고정시켜두고 사용합니다.
이건 운영 중에 스케줄 변경이 거의 없다는 전제를 기반으로 설계되어 있어서 그런 것 입니다. 따라서 DEFAULT_MAX_INTERVAL = 300 (5분)으로 설정되어 있어도 무방함
- 반면 django-celery-beat (django_celery_beat/schedulers.py) 은 스케줄 정보를 Django DB(예: PeriodicTask 테이블)에서 읽어옵니다. 그렇기 때문에, Django Admin을 통해 운영 중에도 실시간으로 스케줄을 변경해도, 변경한 작업이 빠르게 반영이 됩니다.
3.2 전체&대략 적인 beat 흐름
전체적인 beat에 대한 흐름은 아래와 같습니다.
celery beat run → Scheduler.run → tick() → is_due() → apply_async()
4. Task 결과 저장 여부와 구조
django-celery-beat를 사용하면서 Task 결과를 어떻게 저장하고 관리할지에 대한 고민은 데이터베이스에 쌓는 것으로 해결할 수 있습니다.
4.1 django-celery-results
django 세팅에서 CELERY_RESULT_BACKEND를 설정하면 Celery가 작업 결과를 저장하는 방식을 지정할 수 있습니다.
CELERY_RESULT_BACKEND = "django-db"
이때, django-celery-results 패키지를 설치해야 합니다.
pip install django-celery-results
이 설정을 사용하려면 django-celery-results 패키지를 설치하고, Django 앱에 등록해야 합니다.
# settings.py
INSTALLED_APPS = [
"django_celery_results",
]
그리고 마이그레이션을 적용해야 django_celery_results.models.TaskResult 에 대한 테이블이 생성됩니다.
python manage.py migrate
4.2 ignore_result
작업에 대한 결과를 저장하고 싶지 않은경우, 전역 혹은 개별로 설정이 가능합니다.
전역으로 설정하려면, CELERY_TASK_IGNORE_RESULT를 사용합니다.
# settings.py
CELERY_TASK_IGNORE_RESULT = True
개별 Task 에 대해서 설정하려면 아래처럼 ignore_result=True를 설정하여 비활성화할 수 있습니다.
@app.task(ignore_result=True)
def my_task():
...
5. one-off Task
django-celery-beat에서 PeriodicTask 모델에는 one_off라는 Boolean 필드가 있습니다.
이 필드를 True로 설정하면 해당 작업은 한 번만 실행된 뒤 자동으로 비활성화됩니다. 주로 다음과 같은 상황에서 유용하게 쓰일 수 있습니다.
- 특정 시간에 한 번만 실행해야 하는 예약 작업.
- 관리자가 Django Admin에서 즉시 실행한번 실행해보고 마는 작업.
one-off 처리 로직
DatabaseScheduler의 is_due() 내부에서는 다음과 같은 방식으로 one-off 작업을 처리합니다.
# django_celery_beat/schedulers.py
if self.model.one_off and self.model.enabled and self.model.total_run_count > 0:
self.model.enabled = False
self.model.save()
이 로직의 의미는 다음과 같습니다
한 번만 실행되어야 하는 작업이면서, 아직 활성 상태이고, 이미 한 번 실행되었다면 self.model.enabled 를 False로 설정합니다. 즉, 작업이 한 번 실행된 이후에는 자동으로 enabled=False로 설정되기 때문에 더 이상 실행되지 않도록 처리됩니다.
6. 참고자료
- hongreat 블로그의 글을 봐주셔서 감사합니다!^^
- 내용에 잘못된 부분이나 의문점이 있으시다면 댓글 부탁 & 환영 합니다~!
- (하단의 버튼을 누르시면 댓글을 보거나 작성할 수 있습니다.)
