- Published on
Pyscript with Machine Learning
- Authors

- Name
- hongreat
- ✉️hongreat95@gmail.com
0. 들어가며
안녕하세요.
Pyscript 를 실험적으로 사용해보고 머신러닝이란 무엇인가 알아보는 튜토리얼을 만들고 사내 기술블로그 기고했습니다. 이번글의 순서는 아래와 같습니다.
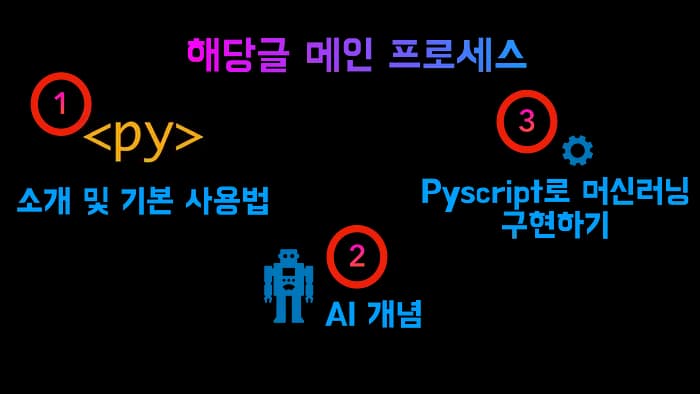
1. pyscript 란?
- 2022년 5월에 anaconda에서 블로그를 통해 새로운 기술을 소개했습니다.(해당 기술에 대해서 언어라고 할지 프레임워크라고 할지 명확히 구분하기 어려운 것 같습니다.)
- python을 html에서 사용할 수 있게 하는 이 기술은 출시된지 얼마 지나지 않은 상태로, 많은 라이브러리를 지원하지는 않습니다.하지만 python 의 라이브러리를 사용할 수 있고, 복잡한 파이프라인을 구현할 필요없이 이를 html 에서 바로 확인 할 수 있다는 것이 매우 매력적이라고 생각합니다.
그럼 먼저 pyscript를 사용해보겠습니다.
기본사용방법
- Pyscript는 별도의 다운로드를 할 필요없이 html에서 단 2줄의 코드로 불러와 사용할 수 있습니다.
- Js 를 사용하듯이 html 파일에서 아래의 코드로 pyscript 를 불러와서 사용할 수 있습니다.
<head>
<meta charset="UTF-8" />
<link rel="stylesheet" href="<https://pyscript.net/alpha/pyscript.css>" />
<script defer src="<https://pyscript.net/alpha/pyscript.js>"></script>
</head>
만약 파이썬의 다른 라이브러리를 사용하고 싶다면 다음을 추가해야합니다.
- 공식 깃허브의 튜토리얼에 따라, 라이브러리를 사용하기 위해서는 기존의 파이썬 프레임워크에서
pip install {library}명령어로 라이브러리를 추가했던 것과는 다르게 <py-env>태그안에서 원하는 라이브러리를 적음과 동시에 사용이 가능해집니다.- 예를들어 numpy 와 matplotlib 라이브러리를 사용하는 방법은 다음과 같습니다.
<py-env>
- numpy # python의 행렬연산 라이브러리
- matplotlib # python의 시각화 라이브러리
</py-env>
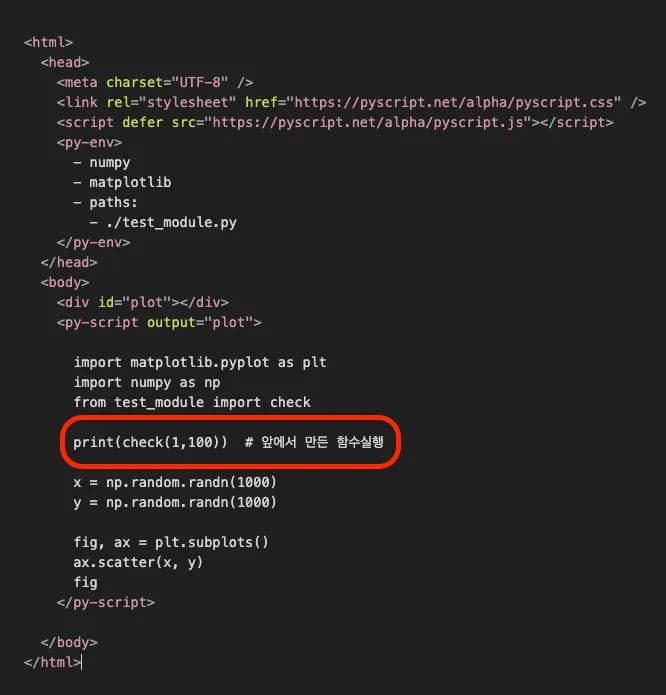
직접 만든 패키지,함수 등을 사용하는 방법은 다음과 같습니다.
간단한 함수를 불러와 사용해보는 예시 코드입니다.
<py-env>
— numpy
— matplotlib
— paths:
— ./test_module.py
</py-env>
- 동일 depth에서 test_module.py 파일을 만들고 내부에 다음과 같은 함수를 선언합니다.
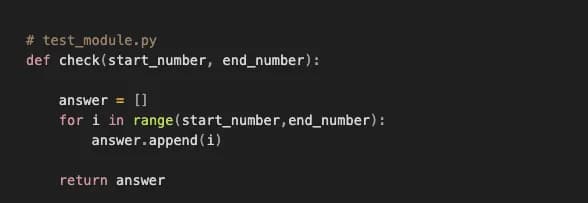
paths:를 사용하여 반복문 함수가 있는 파일을 import 하겠습니다.
2. 인공지능이란?? (a.k.a ML,DL)
인공지능 하면 ‘자동으로 움직이고 생각하는 로봇, 기계’ 등을 먼저 떠올리는 분들이 많습니다.
코로나 이후 인공지능 붐(?)이 일어나면서
‘사람의 일을 대신할 것이다.’ , ‘인공지능의 무서운 발전속도!’ 등
많은 관심이 생긴 것 같습니다.
그렇다면
이 인공지능은 도대체 무엇이며, 어디에 활용되어, 어떤 역할을 할까요??
먼저 인공지능으로 원하는 결과를 얻으려면
어떻게 사용하는 것 인지 아래 그림을 살펴 보겠습니다.

데이터 → 머신러닝/딥러닝 → 결과
- 먼저 올바른 상황에 맞는 데이터를 수집하고 잘 정제 합니다.
- 데이터에 성능이 좋고 적합한 인공지능 모델을 개발 및 적용합니다.
- 최적의 결과를 얻습니다.
정리하면 “양질의 Data 를 활용한 최적의 Ai” 로 좋은 결과를 얻는 것 입니다.
이러한 인공지능(AI)은 크게 머신러닝과 딥러닝으로 구분할 수 있습니다.
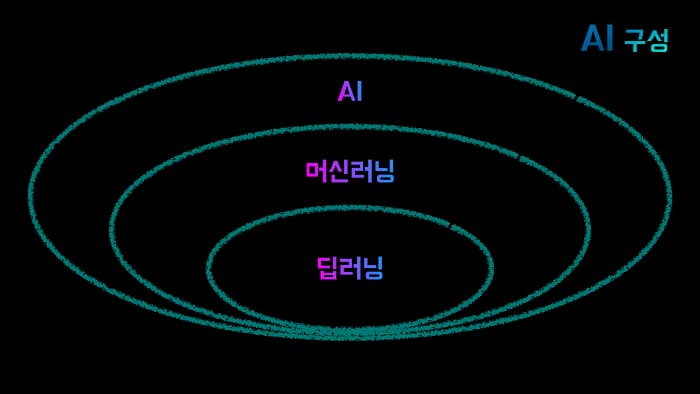
머신러닝(Machine Learning)
사람이 명확하게 구분할 수 없는 많은 지식과 규칙들을
컴퓨터에게 학습시키는 것을 머신러닝 이라고 합니다.
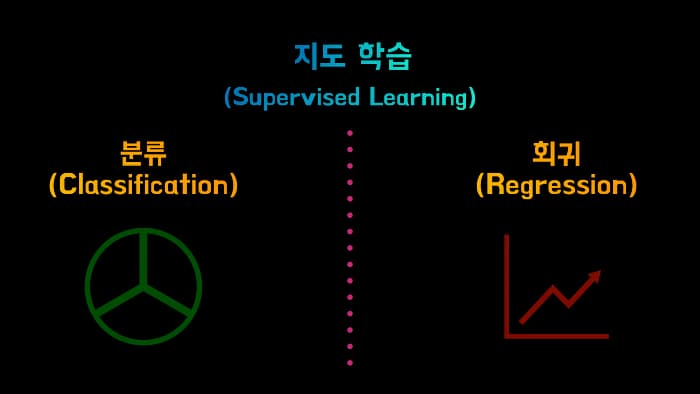
머신러닝은 지도학습, 비지도학습, 강화학습 으로 나뉩니다.

지도학습
분류, 회귀로 나뉩니다.
- 분류의 예로는 스팸 메일을 “구분” 하는 기능이 있고
- 회귀의 예로는 주택가격 예측 등의 “예측” 의 기능 을 합니다.
비지도학습
지도학습처럼 “~할 때 정답(label)” 이 있는 것 아니라!
label이 없는 상태에서 학습 시키는 것을 말합니다.
- 이렇게 학습된 모델(군집;clustering)등을 활용해 어느 군집에 속하는 것인지 판단 할 수 있습니다.
강화학습
강화학습은 학습 모델이 더 많은 보상을 얻는 방향으로
패턴을 학습하는 방식입니다.
딥러닝(Deep Learning)
일상에서 흔히 찾아볼 수 있는 인공지능 기술은 대부분 딥러닝 입니다.
- 딥러닝에 사용되는 인공신경망 알고리즘에는심층 신경망(DNN), 합성곱 신경망(CNN), 순환 신경망(RNN) 을 포함해 많은 알고리즘이 있습니다.
- 근본적인 원리는 인간의 뇌(신경망)을 모방하여 만들어진 알고리즘이라고 할 수 있습니다.
딥러닝의 기술은 용도에 따라서
**컴퓨터 비젼(CV) 과 자연어처리(NLP)**로 나뉩니다.
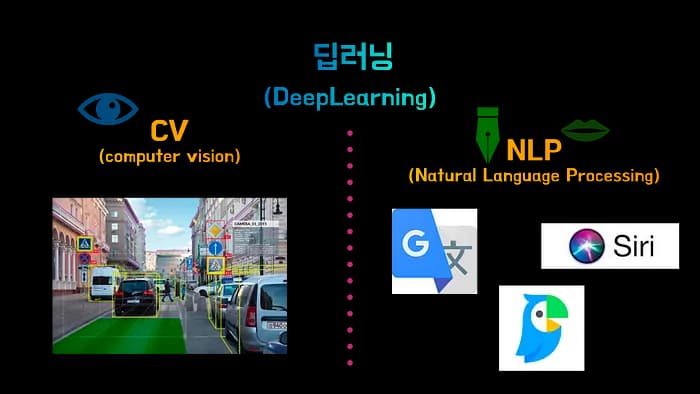
- 컴퓨터 비젼은 인간이 사물을 보고 어떤 물건인지 구분할 수 있듯이컴퓨터에게 시각적인 데이터를 학습시킨 후 구분하는 용도로 많이 쓰입니다.
- 자연어 처리는 컴퓨터에게 글(문장)을 학습시켜 뜻을 이해시키고 감성분석을 하는 등의 기능으로 활용됩니다.
3. Pyscript 로 구현하는 비만도 분류
pyscript와 scikit-learn 을 이용해서 간단한 비만도 분류를 구현했습니다.
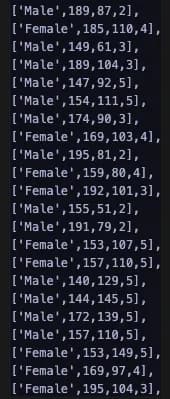
- 약 20개 정도의 데이터를 pandas의 dataframe으로 변환하여pyscript에서 Data를 다루게 했습니다.
- 대표적인 머신러닝 라이브러리인 sklearn을 활용해KNeighborsClassifier의 모델로 튜토리얼을 만들었습니다.
- 독립/종속 변수는 다음과 같습니다
성별(Male/Female), 키, 몸무게⇒비만도{1: “깡마름”, 2: “마름”, 3: “보통”, 4: “통통”, 5: “뚱뚱”}
아래 링크에서 간단한 비만도 테스트와 Part.1의 기본사용방법결과를 확인할 수 있습니다.
KNeighborsClassifier 란?
위의 소스코드에서 KNeighborsClassifier 모델을 이용했습니다.
해당 모델은 KNN 알고리즘에 기반한 모델로
KNN(K Nearest Neighbor)은K 최근접 이웃 알고리즘이라고도 불립니다.
이 알고리즘을 아래의 그림을 통해 이해하는 시간을 가져보겠습니다.

노란집이 새로운 데이터이고 K(임의의 수)가 3일때,
“이 노란집은 초록색집과 파란색집 중 어떤 집에 속할 것인가?!”
라는 질문이 있습니다.
즉, 초록색집 이냐, 파란색집 이냐 를**“분류” 하는 문제**입니다.
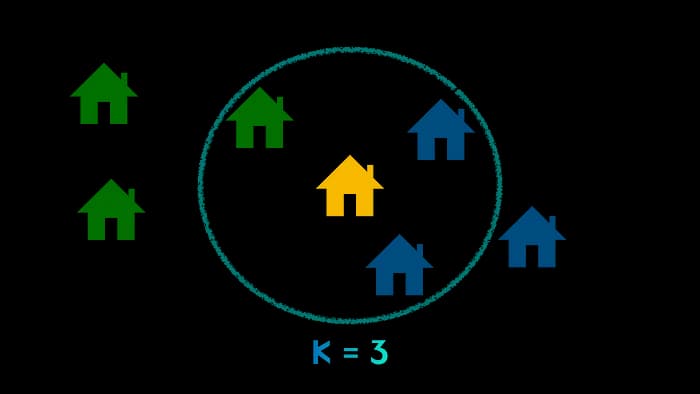
이 때,K = 3이라고 가정하면, 가장 가까운3개의 집들 중에서 더 많은 집의 집합(파란집)에 속하는 것 입니다.
4. 맺음말
데이터를 어떻게 활용할 것 인가? _Data Science..
인공지능 분야? _R&D의 영역..
Basic한 ML의 프로세스는 다음과 같다고 생각합니다.
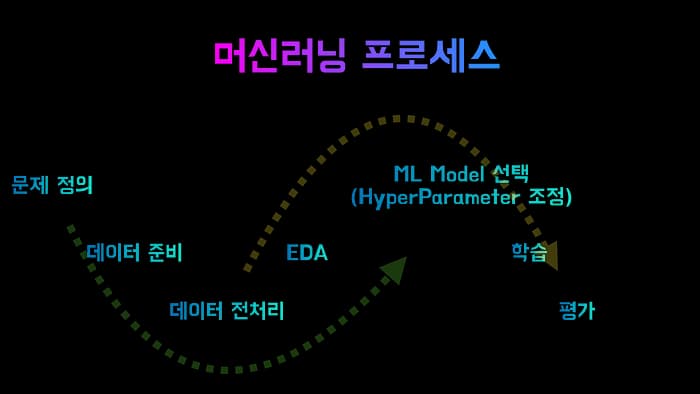
해당 튜토리얼로 보는 한계..
- 간단한 예시를 구축하기 위해 데이터를 정적으로 활용했습니다.
- 꼭 데이터 셋이 많다고 좋은 것은 아니지만다양한 데이터의 표본은 보다 정확도를 올릴 수 있고, 데이터 셋이 적다보니 분포 상에서 Skew가 높을 수 있습니다.
- 일반적인 키,몸무게 외에 혈액형,생활 환경, 식사량 등의 독립변수가 있었다면 새로운 특징을 갖는 변수가 통계적으로 유의미 한 것인지 발견할 수도 있었을 것 입니다.
간단한 튜토리얼을 통해
머신러닝 모델을 활용해서 (분류 | 예측)을 해봤습니다.
그렇다면..
이 머신러닝 모델은 어떻게 만든 것일까요??
이런 상황에서 이 모델을 왜 사용하게 된 것일까요??
- 코딩으로 머신러닝을 동작했지만머신러닝과 딥러닝의 모델은복잡한 이론을 기반으로 행렬연산과 수식을 통해 수학적, 통계적으로 결정되고 만들어 집니다.
제 생각은 다음과 같습니다.
높은 수준의 머신러닝을 제대로 활용하려면데이터 분석이 필요합니다.
- 예를 들어 비만도 데이터를 사용했을 때이 데이터가 “비만도에 대한분류|예측을 할 수 있는 데이터” 라고판단할 수 있는 근거가 필요합니다.(데이터의 column과 row이 많아 질수록, 모델의 성능과 방향성은 매우 달라 질 수 있습니다.)
저는 MLops에 목표를 갖고, 백엔드 개발에 몰두하며 살고 있습니다.
더 성장해서 흥미로운 주제로 다시 돌아오겠습니다!!
참고할 만한 링크
- hongreat 블로그의 글을 봐주셔서 감사합니다!^^
- 내용에 잘못된 부분이나 의문점이 있으시다면 댓글 부탁 & 환영 합니다~!
- (하단의 버튼을 누르시면 댓글을 보거나 작성할 수 있습니다.)
