- Published on
S3 와 Lambda Trigger 를 이용한 파이프라인과 tmp dir
- Authors

- Name
- hongreat
- ✉️hongreat95@gmail.com
AWS의 자원을 이용해서 S3에 특정 파일이 업로드되면 Lambda 함수를 실행하는 Trigger Action을 만들 수 있고, 이를 파이프라인으로 활용했습니다.
구체적으로 MLops 는 아니며, 프로젝트 내 파일서빙에 대한 파이프라인 입니다.
이번에는 S3와 Lambda를 활용한 Trigger를 어떻게 만드는지 가볍게(?)살펴보고 어떻게 활용했는지 알아보겠습니다.
1. Flow
먼저, AI 와 맞닿은 레이어에서 모델을 서빙할 수 없고 결과 자료구조(폼)를 변경할 수 없는 큰 제약조건이 있었습니다.
때문에 다른 외부 자원(S3와 같은)을 활용해 무엇인가 만들어야했고, 프로젝트에서 Storage로 사용되는 Aws S3 를 활용해서 (있는 자원을 활용하자!) 만들기로 했습니다.
결과적으로 만들어진 파이프라인은 아래와 같으며, 이벤트 처리 부분이 주요한 파이프라인이라고 할 수 있습니다.
 참고:
참고: 1.1 파일 업로드 확인
- 프론트엔드 → 백엔드 로 생성한 프로젝트(project) 단위와 인공지능 실행에 필요한 파일들을 업로드 합니다.
- 이때 S3의 경로를 user와 project 를 적절하게 구성해서 분기합니다.
1.2 AI
- 배치로 파일이 업로드 되는지 감지하고 AI 작업이 마무리되면 결과물(.zip 파일) 을 S3에 업로드 합니다.
- 경로 예시는 다음과 같습니다. /user_id/result.zip
1.3 이벤트 처리
완료 이벤트(S3에 특정 파일이 업로드)가 발생하면, Lambda 함수를 실행하는 Trigger 를 구축합니다.
- 여기서 특정 파일이란 규칙을 정해두고 버킷-접두어 접미어 설정으로 파일을 특정하는 것을 말합니다.
Lambda 함수 내에서 zip 파일 압축해제하고, 파일종류(텍스트, 이미지, Json)에 따라 S3에 재 업로드 합니다.
Lambda 액션의 결과 에 따라 백엔드(WAS) 로 결과를 알리기 위한 API 를 발송합니다.
2. 람다(Lambda) 트리거
람다 생성해야하는데, 크게 2가지가 중요합니다.
첫번째는 S3에 대한 이벤트를 수신 해야하고, 두번째는 그럴 수 있도록 IAM권한을 부여해야 한다는 것 입니다.
2.1 람다 생성
로직을 처리할 람다 함수를 생성해야하는데, 저는 Python 3.9 이상의 환경을 사용했습니다.
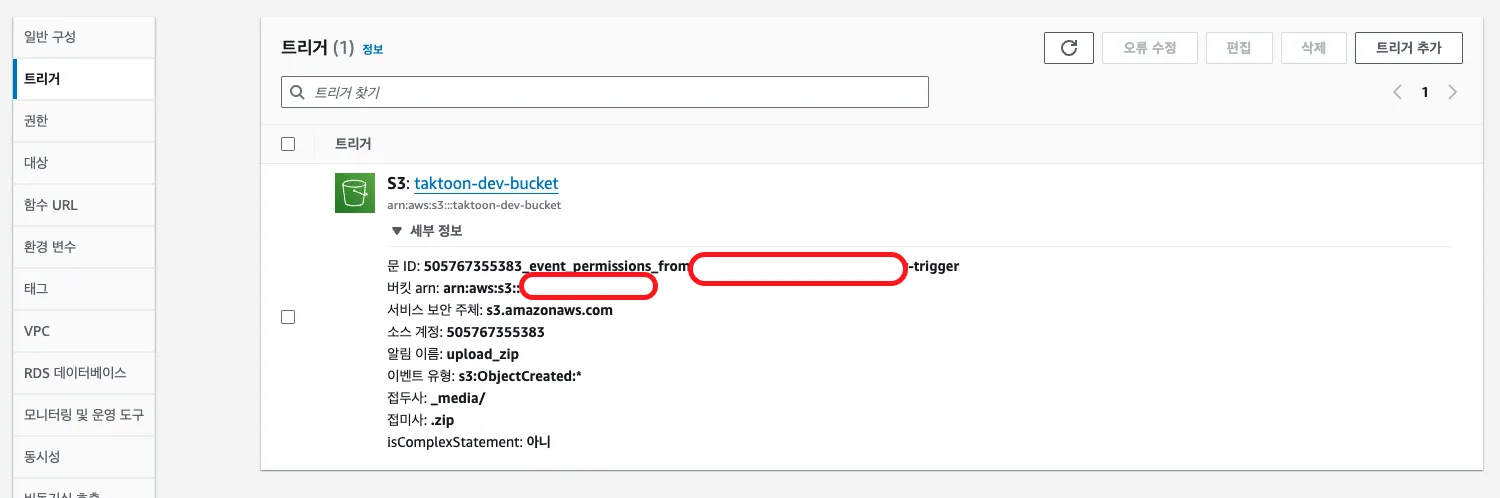
2.2 S3 이벤트 트리거 설정
트리거 설정은 두 곳에서 할 수 있습니다.
- 람다 콘솔
- S3 콘솔 (권한설정만 잘 해주면 어디서 지정해야하는지는 크게 중요하지 않습니다.)
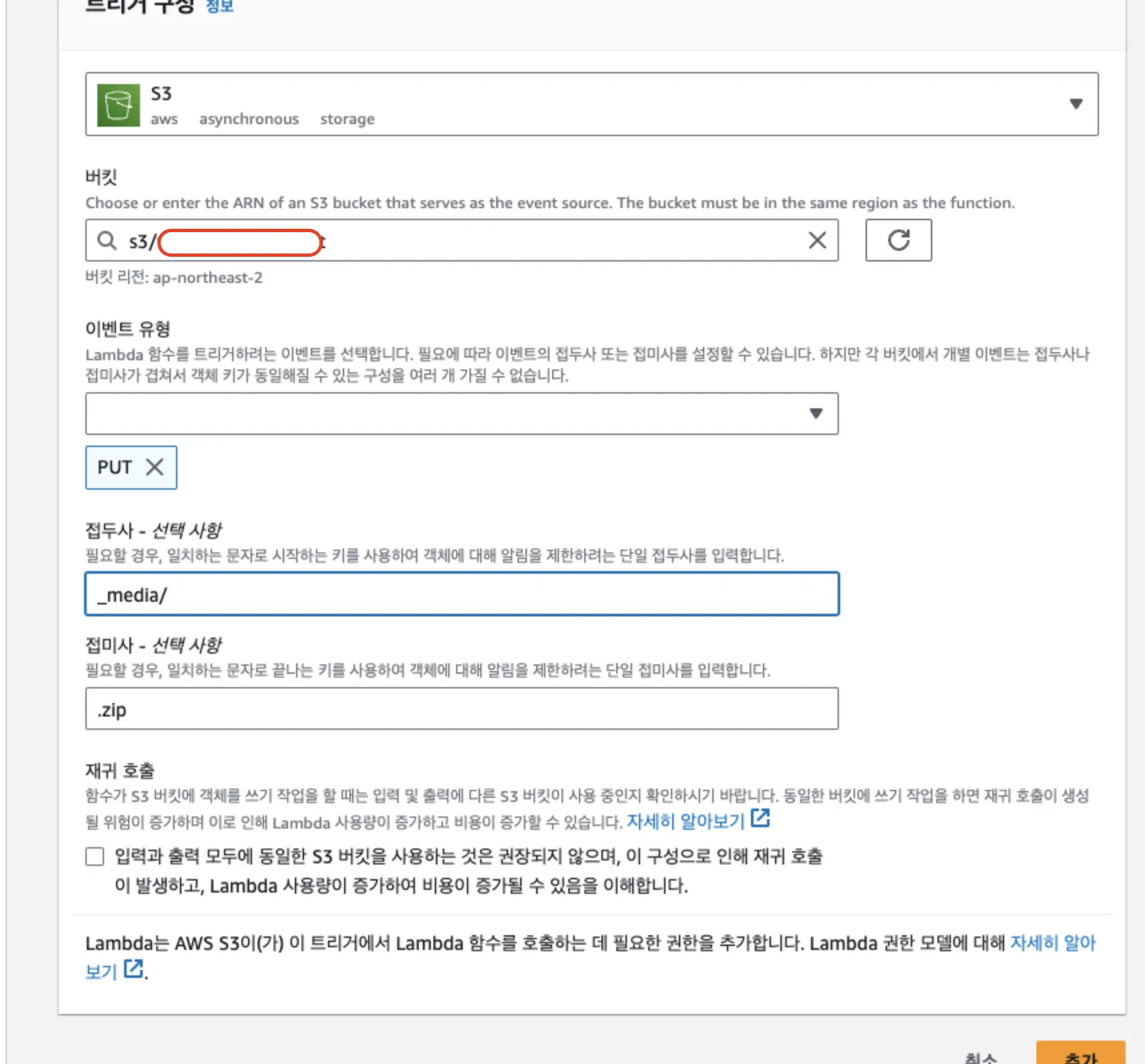
- Lambda 함수 설정 페이지에서 Add trigger 버튼을 클릭합니다.
- Trigger configuration에서 S3를 선택합니다.
- Bucket에서 파일을 업로드할 S3 버킷을 선택합니다.
- Event type을 PUT으로 설정하여 파일 업로드 시 Lambda 함수가 실행되도록 합니다.
2.3 접두어(Prefix), 접미어(Suffix)
S3에 수많은 파일이 업로드 될 수 있기 때문에, 특정한 규칙으로 업로드 되는 경우만 람다 함수가 실행 될 수 있도록 설정 할 수 있습니다.
접두어(Prefix), 접미어(Suffix)를 설정하여 특정 폴더 또는 파일 형식에 대해서만 트리거되도록 할 수 있습니다. 모든 .zip 파일에 대해 트리거되도록 하려면 Suffix에 .zip를 입력합니다.
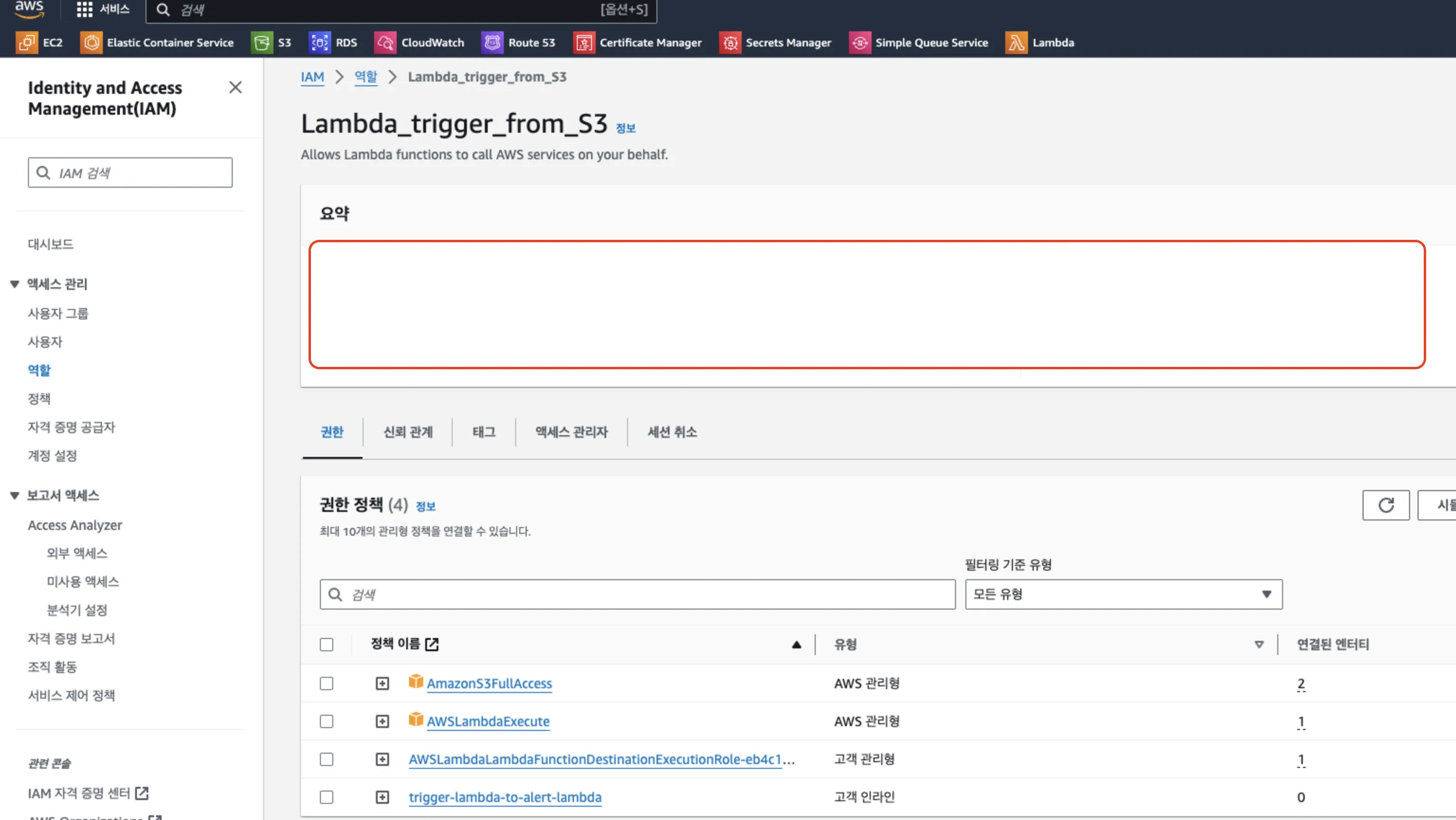
2.4 Lambda 함수의 IAM 역할 설정
S3에 전체적으로 접근할 수 있는 권한과 Lambda Invoke에 대한 권한으로 트리거를 작업이 수행 가능합니다.
3. zip 압축해제 및 업로드
압축해제 과정에서 파일을 (바이너리 상태로) 바로 S3 로 업로드 하려고 해봤으나, zip 파일에 상당히 많은 파일이 있었습니다.
초반 기획은 MB단위였는데, GB단위로 늘어났습니다.
람다 내부의 코드로서 이 코드단에서 파일의 압축을 해제 해야하는데, 압축을 해제해서 임시로 담아둘 공간이 필요합니다.
마침 Lambda에서 tmp 디렉토리를 사용하는 것에 대한 문서가 있었습니다.
3.1 코드
import json
import os
import zipfile
import shutil
import time
import boto3
S3_CLIENT = boto3.client("s3")
LAMBDA_CLIENT = boto3.client("lambda")
ZIP_EXT = ".zip"
TMP_ZIP_PATH = "/tmp/result.zip"
EXTRACT_FOLDER_PATH = "/tmp/extracted"
RESULT_FOLDER = "/result/"
ALERT_API_FUNCTION = "alert-api" # Lambda_2 호출
ALERT_S3_FUNCTION = "alert-s3" # Lambda_2 호출
# tmp 초기화 코드
def clear_tmp_directory():
tmp_dir = '/tmp'
for filename in os.listdir(tmp_dir):
file_path = os.path.join(tmp_dir, filename)
try:
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path)
elif os.path.isdir(file_path):
shutil.rmtree(file_path)
except Exception as e:
print("실패하는 경우 처리")
def lambda_handler(event, context):
invoke_slack(event=event,context=context
start_time = time.time()
bucket, key = get_bucket_and_key(event)
print(f"파일 업로드: {key} bucket: {bucket}")
clear_tmp_directory() # 폴더 초기화
if ZIP_EXT in key:
process_zip_file(bucket, key)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"실행에 걸린 시간: {elapsed_time} 초")
invoke_slack(contents=contents)
return {"statusCode": 200, "body": "성공 응답"}
invoke_slack(contents="실행과정 로그내용")
raise Exception(exception_info)
def get_bucket_and_key(event):
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = event["Records"][0]["s3"]["object"]["key"]
return bucket, key
def process_zip_file(bucket, key):
download_path = download_zip_file(bucket, key)
unzip_files(download_path)
upload_files(bucket, key)
invoke_lambda_function(key)
def download_zip_file(bucket, key):
S3_CLIENT.download_file(bucket, key, TMP_ZIP_PATH)
print("다운로드 완료 및 실행준비 단계, 이 단계에서 tmp 를 이용")
return TMP_ZIP_PATH
def unzip_files(zip_file_path):
os.makedirs(EXTRACT_FOLDER_PATH, exist_ok=True)
with zipfile.ZipFile(zip_file_path, "r") as zip_ref:
zip_ref.extractall(EXTRACT_FOLDER_PATH)
def upload_files(bucket, key):
upload_path = "/".join(key.split("/")[:-1])
for root, dirs, files in os.walk(EXTRACT_FOLDER_PATH):
for file in files:
upload_file_to_s3(bucket, file, root, upload_path)
def upload_file_to_s3(bucket, file, root, upload_path):
local_path = os.path.join(root, file)
s3_key = os.path.relpath(local_path, EXTRACT_FOLDER_PATH)
s3_upload_path = upload_path + RESULT_FOLDER + s3_key # 업로드되는 경로 지정 upload_path/s3_key
if s3_key.split(".")[-1] == "txt":
S3_CLIENT.upload_file(local_path,bucket,s3_upload_path,ExtraArgs={"ContentType":"text/plain; charset=utf-8"})
else:
S3_CLIENT.upload_file(local_path, bucket, s3_upload_path)
def invoke_lambda_function(key):
print("별도 로직")
def invoke_slack(event=None, context=None,contents=None):
print("별도 로직")
3.2 AWS Lambda의 /tmp 디렉토리
임시 저장소로서의 역할
- Lambda 함수는 실행되는 동안
/tmp디렉토리를 임시 저장소로 사용할 수 있습니다. /tmp디렉토리를 사용하면 파일을 임시로 저장하고 처리할 수 있어, 여러 파일을 한 번에 처리하거나 중간 결과를 저장하는데 유용합니다.
- Lambda 함수는 실행되는 동안
비용 절감
- 압축 파일의 내용을 직접 S3에 업로드하는 경우, 각 파일을 별도의 S3 PUT 요청으로 업로드해야 합니다. 이는 요청 횟수에 따라 비용이 발생할 수 있습니다.
/tmp디렉토리에 압축을 해제한 후, 여러 파일을 한 번에 처리하여 업로드하는 것이 비용 효율적일 수 있습니다.
처리(논리)의 단순화
- 압축 파일을
/tmp디렉토리에 해제하고 각 파일을 순차적으로 처리하거나 병렬로 처리하는 것이 논리적으로 더 간단할 수 있습니다. - 이는 오류 처리나 예외 상황에 대한 대응을 더 쉽게 할 수 있게 해줍니다.
- 압축 파일을
참고한 문서
- hongreat 블로그의 글을 봐주셔서 감사합니다!^^
- 내용에 잘못된 부분이나 의문점이 있으시다면 댓글 부탁 & 환영 합니다~!
- (하단의 버튼을 누르시면 댓글을 보거나 작성할 수 있습니다.)
