- Published on
SerializerMethodField와 for문에서 query를 최적화 한 사례
- Authors

- Name
- hongreat
- ✉️hongreat95@gmail.com
기존에 작성된 코드를 점검하면서 ORM 사용만으로, Serializer를 보완하는 것만으로도 개선할 점이 많았습니다. 개선 작업에서 프론트엔드의 추가적인 작업 없이 기존 API 스키마를 유지하면서도 성능을 높이는 개선 방식으로 문제를 해결한 과정을 기록합니다.
- Django의 models.Manager와 기본 ORM으로 해결할 수 있는 문제
- View 로직의 기존 문제와 SerializerMethodField와 annotate의 선택
- N+1 문제가 심각한 이유와 serializer 에 대한 생각
- 참고 자료
Django의 models.Manager와 기본 ORM으로 해결할 수 있는 문제
models.Manager는 모델에 대한 쿼리 작업을 정의하며 별다른 설정을 하지않아도 기본으로 ORM 은 이 Manager를 통해서 관리되도록 하는 클래스입니다. 즉 모델 클래스마다 기본적으로 제공되며, 일반적으로 사용되는 데이터 조회 로직을 별도의 메서드로 정의하여 쿼리를 캡슐화하고 재사용성을 높이는 역할을 합니다. 따라서 쿼리의 효율성을 높이기 위해서는 models.Manager를 잘 활용한다면 코드가 간결해지며 추상화 수준이 높아지지만, 반대로 잘못 사용하면 성능 문제를 야기할 수 있습니다.
for 안에서 N+1 문제 발생
기존의 매니저 클래스(models.Manager)에서 특정 사용자가 관리하는 장소(place)에 대해 필터링할 때, 각 장소마다 쿼리를 반복적으로 실행했습니다.
예를 들어, 아래와 같은 기존 코드가 있었습니다.
class SomeLogModelManager(models.Manager):
def active_for_user_places(self, user):
some_ids = []
managed_places = user.place_managers.all()
for manager in managed_places:
some_ids += list(
self.filter(place_id=manager.place.id).values_list("id", flat=True)
)
some_ids = list(set(some_ids))
return self.filter(id__in=some_ids, is_active=True)
즉, 각 반복을 순회할때 마다 무자비한 쿼리를 발생시키는 문제가 있었습니다. 하지만 결국 반복을 통해 가져오는 것은 id 이고, 이것을 바로 filter해주면 쿼리를 한번만 실행할 수 있었습니다.
def active_for_place_manager(self, user):
place_ids = user.place_managers.values_list('b_place_id', flat=True)
return self.filter(b_place_id__in=place_ids, is_active=True)
View 로직의 기존 문제와 SerializerMethodField와 annotate의 선택
기존의 View 로직 또한 Serializer에 필요한 데이터를 미리 준비하지 않고, 매번 Serializer에서 접근할 때마다 추가 쿼리를 유발했습니다. 이러한 구조는 데이터 조회가 반복될 때마다 성능을 저하시키는 원인이 됩니다.
Serializer에서 추가적으로 필요한 필드가 필요한 경우 대부분은 annotate를 사용하는 것이 이상적 이라고 생각합니다.
첫번째 가장 큰 이유는 필드의 타입을 명확히 정의할 수 있기 때문입니다. SerializerMethodField는 CharField 로만 정의되어있기 때문에, 사실 실제로 데이터 타입이 무엇인지 알 수 없습니다.
하지만 이번 경우에는 이미 프론트엔드가 SerializerMethodField를 사용하는 형태로 데이터를 받고 있었기 때문에, 프론트엔드의 추가 작업을 최소화하고자 기존의 SerializerMethodField 의 get_user_info 메서드를 그대로 유지했어야만 했습니다. 대신 데이터를 효율적으로 전달하는 방식을 고민했습니다.
Serializer Context를 활용한 데이터 전달
get_user_info 메서드를 그대로 유지하되, 성능 문제를 해결하기 위해 데이터를 Serializer 내부가 아닌 View의 get_serializer_context를 통해 미리 준비하여 전달하기로 결정했습니다. 이 방법으로 각 Serializer 호출 시 추가 쿼리가 발생하지 않아도 되었습니다.
def get_serializer_context(self):
context = super().get_serializer_context()
membership_ids = self.get_queryset().values_list('membership_id', flat=True).distinct()
context['memberships'] = {
m.id: m for m in Membership.objects.filter(id__in=membership_ids).select_related('pass_obj', 'pass_obj__user')
}
return context
이렇게 Serializer에 데이터를 전달하기 때문에, Serializer 내부에서 추가적인 데이터 접근을 최소화합니다. self.context 를 통해 전달된 데이터를 활용하여, id를 통해 맵핑된 데이터를 가져올 수 있습니다. 작업한 Serializer 코드 예시는 다음과 같습니다.
def get_user_info(self, obj):
memberships = self.context.get('memberships', {})
membership = memberships.get(obj.membership_id)
if membership and membership.pass_obj:
serializer = UserInfoSimpleSerializer(membership.pass_obj.user)
return serializer.data
return {}
N+1 문제가 심각한 이유와 serializer 에 대한 생각
이전에 serializer가 무거워서 성능이 떨어진다는 얘기를 많이 들었었는데, 개중에는 N+1 문제를 발생시키는 경우가 많았습니다. 그 안에서의 SerializerMethodField 사용도도 빈번했습니다.
Django의 ORM은 쿼리를 최소한으로 발생시킬 때 가장 효율적입니다. 하지만 위처럼 반복문 내에서 ORM을 호출하면 장소 수만큼 쿼리가 추가로 실행됩니다. 이로 인해 데이터가 많아질수록 급격히 성능이 저하됩니다. 한번만 통신하여 해결할 수 있는 문제를, 불필요한 호출로 시간과 비용이 낭비 되는 것 입니다.
이번에 이런 최적화를 통해 결과적으로 15~20초의 API 속도를 111ms로 줄일 수 있었습니다.
- AS-IS
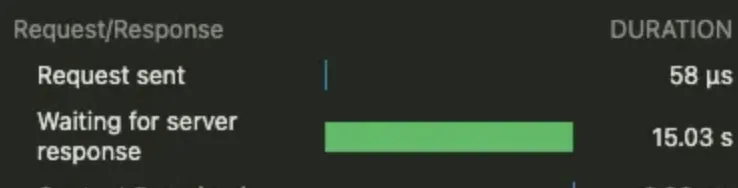
- TO-BE
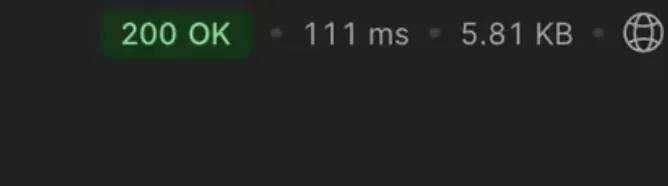
Framework 를 오래사용하면서 느낀 점은 깊게 알수록 중요한 문제를 ORM의 기본 동작 방식을 이해하는 것만으로도 해결 할 수 있다는 것 입니다. Django 한정되기는 하지만 Serializer를 잘 사용해야 한다는 점 입니다.
참고 자료
- hongreat 블로그의 글을 봐주셔서 감사합니다!^^
- 내용에 잘못된 부분이나 의문점이 있으시다면 댓글 부탁 & 환영 합니다~!
- (하단의 버튼을 누르시면 댓글을 보거나 작성할 수 있습니다.)
